Large-Scale Text-to-Image Model with Inpainting is a Zero-Shot Subject-Driven Image Generator
CVPR 2025

Subject-driven text-to-image generation aims to produce images of a new subject within a desired context by accurately capturing both the visual characteristics of the subject and the semantic content of a text prompt. Traditional methods rely on time- and resource-intensive fine-tuning for subject alignment, while recent zero-shot approaches leverage on-the-fly image prompting, often sacrificing subject alignment. In this paper, we introduce Diptych Prompting, a novel zero-shot approach that reinterprets as an inpainting task with precise subject alignment by leveraging the emergent property of diptych generation in large-scale text-to-image models. Diptych Prompting arranges an incomplete diptych with the reference image in the left panel, and performs text-conditioned inpainting on the right panel. We further prevent unwanted content leakage by removing the background in the reference image and improve fine-grained details in the generated subject by enhancing attention weights between the panels during inpainting. Experimental results confirm that our approach significantly outperforms zero-shot image prompting methods, resulting in images that are visually preferred by users. Additionally, our method supports not only subject-driven generation but also stylized image generation and subject-driven image editing, demonstrating versatility across diverse image generation applications.
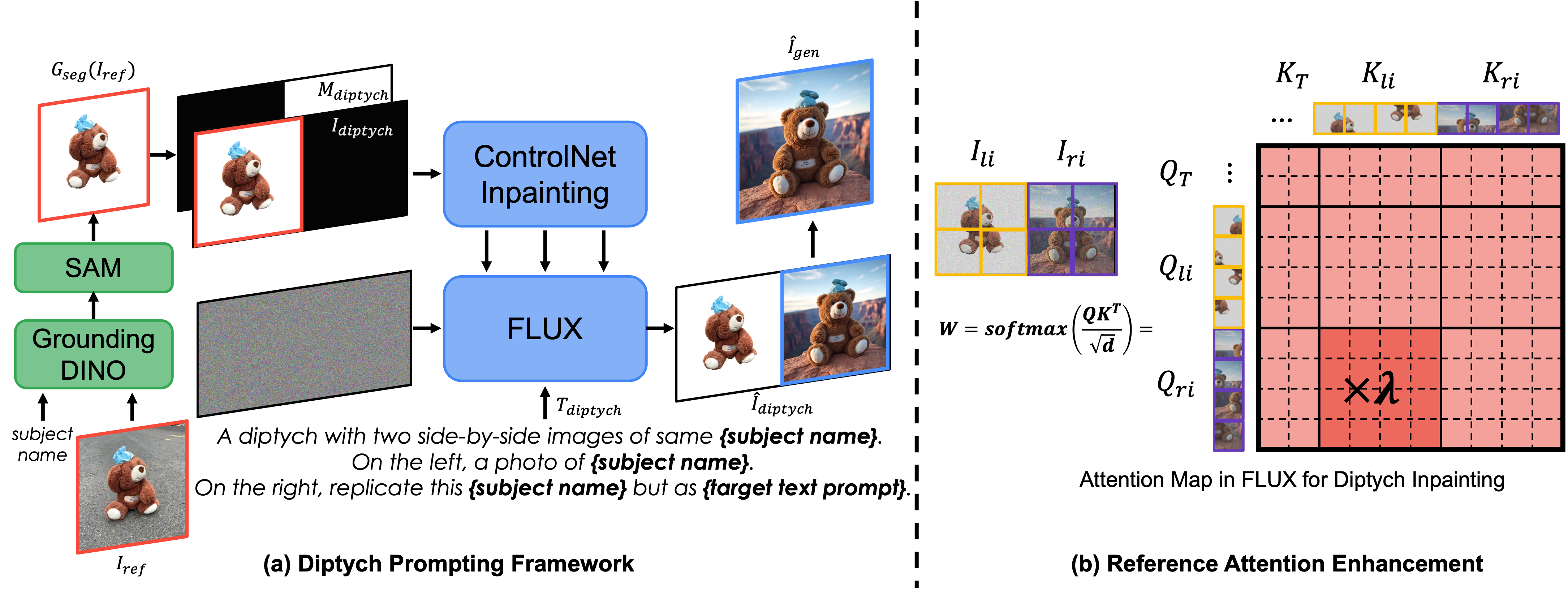
A 'Diptych' is an art term referring to a two-paneled artwork in which two panels are displayed side by side, each containing interrelated content. Given the reference subject image and target text prompt describing the desired context, our Diptych Prompting begins by composing the triplet: an incomplete diptych containing the reference subject image in the left panel, text prompt describing the diptych with target context, and the binary mask specifying the right panel as the inpainting target. Subsequently, the right panel is completed through text-conditioned inpainting, generating an image that incorporates both the target subject and desired context effectively. In the inpainting process, we remove the background from the reference image using Grounding DINO and SAM to isolate only the subject related information in the reference image. Additionally, to preserve fine-grained details of the subject in the generated image, we enhance the reference attention by rescaling the attention weights between the right panel query and the left panel key.
Our Diptych Prompting achieves high-quality subject-driven text-to-image generation, satisfying both subject alignment and text alignment in a zero-shot manner across diverse subjects and situations.

Despite using an inpainting approach without any specialized training for subject-driven text-to-image generation, Diptych Prompting significantly outperforms encoder-based zero-shot methods. Its superiority is evident in capturing the granular details of reference subjects, even in challenging examples with characteristic fine details, such as a ‘monster toy’ or ‘backpack’.

Diptych Prompting can be extended to stylized image generation by using a style image as the reference. The generated images accurately reflect the stylistic features of the reference style image, such as color scheme, texture, and layout.

Diptych Prompting enables subject-driven image editing by placing the reference subject image on the left panel and the editing target image on the right panel of the incomplete diptych. By masking only the desired area in the right panel and applying diptych inpainting, the reference subject from the left panel is seamlessly generated in the masked region on the right panel. The edited images effectively preserve the unmasked areas while integrating the desired subject into the target region.